
Medical publications
Dec 21, 2025
Biological Age
Read more


How we source, rank, and refresh the medical evidence behind Evidence AI.

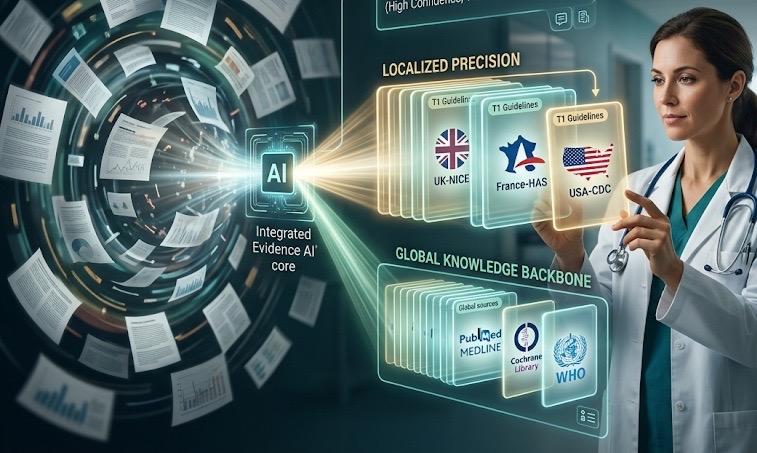
ElfieCare Evidence AI is built on a curated, governed medical knowledge system — not a general-purpose search engine. Every response is grounded in verifiable external sources, classified by evidence strength, and kept current through structured review.
This page explains what powers it.
Evidence AI draws from a curated registry of medical sources, organized into three layers.
These universal sources underpin every clinical query, regardless of a physician's location.
JAMA Network Open, Journal of Medical Internet Research (JMIR), BMC Medicine, PLOS Medicine, Frontiers in Medicine, Diabetes Care, and others that publish under open licenses without commercial restrictions.
For leading journals where full-text access requires licensing, we index structured abstracts available through PubMed. These contain key findings, study design, effect sizes, and clinical conclusions. Each abstract-sourced item is transparently marked so that the system can disclose the limitation.
Evidence AI indexes clinical practice guidelines from major international medical associations and specialty bodies where their published guidelines are openly available.
Some specialty society guidelines require commercial licensing agreements. Where these are not yet in place, the system does not ingest the content. Where joint publications or consensus reports are available through open-access channels, those specific items are included.
Evidence AI is geo-aware. It uses the physician's country and specialty to prioritize local regulatory and guideline sources over global ones.
We index sources from national health authorities, drug regulators, and local clinical guideline bodies across our launch markets, including:
Additional local sources cover markets across Latin America, the Middle East and North Africa, Sub-Saharan Africa, and Southeast Asia. The full local source list is maintained internally and expanded as new markets are supported.
We are transparent about our boundaries.
A number of important medical guidelines and reference databases are protected by copyright or licensing terms that restrict commercial use. We respect these restrictions. Where licensing agreements are not in place, the content is not ingested — regardless of its clinical value.
We are actively pursuing partnerships to expand coverage where licensing permits.
The system does not index:
Every source entering the system must pass a Source Qualification process that verifies legitimacy, authority class, document type, and publication freshness before extraction begins.
Not all evidence carries equal weight. A meta-analysis of multiple randomized controlled trials is stronger than a single case report. A country-specific guideline takes precedence over a global recommendation for a doctor in that country. Evidence AI encodes these distinctions structurally.
Every knowledge object is classified into one of five evidence tiers:
Tier | Type | Examples
T1 | Clinical guidelines — region-matched or global | National authority guidelines, WHO recommendations
T2 | Systematic reviews and meta-analyses | Cochrane reviews, high-quality evidence syntheses
T3 | Primary trials | Randomized controlled trials
T4 | Observational evidence | Cohort studies, case-control studies
T5 | Consensus and lower-tier support | Expert opinion, case series, consensus statements
Where applicable, evidence objects are further characterized using the GRADE (Grading of Recommendations, Assessment, Development, and Evaluations) framework, which captures evidence certainty, strength of recommendation, and individual quality dimensions such as risk of bias, inconsistency, indirectness, and imprecision.
When a query returns evidence from multiple sources, the system applies structured resolution rules:
Each knowledge object carries a composite confidence score derived from two components:
This score determines retrieval behavior:
When evidence is insufficient or absent, the system is designed to state that explicitly and offer structured query refinements — rather than generate a speculative answer.
Medical evidence has a shelf life. Guidelines are updated, new safety alerts are issued, and once-standard treatments are superseded. A static knowledge base decays silently. Evidence AI addresses this through five interlocking mechanisms.
Every knowledge object is assigned a review cadence based on clinical risk and expected volatility:
Class | Frequency | Scope
A | 3–6 months | High-risk, fast-changing evidence — therapy guidelines, drug safety alerts
B | 6–12 months | Core clinical guidelines and common conditions
C | 12–24 months | Stable foundational knowledge
D | On-demand | Low-priority or historical content
Scheduled cadence is supplemented by event-driven review triggers:
The freshness component of each object's confidence score decays over time, calibrated to its review cadence. Fast-moving evidence (Class A) decays more rapidly than stable knowledge (Class C/D). If an object's confidence falls below a safe threshold, the system is designed to automatically flag it for review and restrict its use in clinical outputs.
Each knowledge object exists in one of four states:
Evidence objects are maintained by qualified clinical reviewers. High-risk objects are subject to dual review. Disagreements between reviewers are escalated and must be resolved before an object is approved for use. Review events are recorded for auditability.
The system also monitors for conflicts between knowledge objects. When a new guideline contradicts an existing one, the contradiction is flagged and routed for review. At the physician-facing layer, unresolved conflicts are presented with both viewpoints and citations — the system is designed to let the clinician decide.
For professional use only. ElfieCare Evidence AI synthesizes medical literature based on clinical parameters. It does not provide medical diagnoses or treatment mandates. Final clinical judgment remains with the healthcare provider.

